Jako że artykuł o stanie BASICa (w porównaniu z popularnymi językami tamtego czasu), kiedy Dijkstra zaczął być znany jako jego największy nienawistnik stał się najpopularniejszym wpisem na tej stronie (zapamiętać: hejt dobrze się “sprzedaje”, co najmniej przez 50 lat), wypada podjąć kilka luźno pozostawionych wątków: jakie były alternatywy? Jak dobre były? Czy nadal je mamy? (Co o nich wiedzą? Dowiedzmy się)
Zastrzeżenie: Opisuję początki tych języków i ich pierwsze wersje – rzeczy, które zostały wydane i stały się popularne kilka lat przed moim urodzeniem. Nie wahaj się sugerować poprawki, jeśli zauważysz coś nieprawidłowego!
Omówilismy już duże (wtedy) języki, które nigdy nie umarły: PL/I, COBOL, Fortran i oczywiście BASIC. Ale kontynuując obietnicę (cyt. “Te języki to nie wszystko, co było na rynku w latach 70., ale były one rzeczywiście najpopularniejszymi! Poznamy oddzielnie te, które dopiero się pojawiały.”)… Najwyższy czas, i tym razem gramy w otwarte karty, bez tytułu-clickbaitu. Prawie.
To, co już znamy – BASIC
Szybko podsumowując artykuł o zaletach i wadach BASICa:
- BASIC, patrząc czysto na język, a nie entuzjazm z jakim szedł w parze, miał pewne wady:
- Brak struktury kodu (z wyjątkiem możliwości skoku do linii kodu za pomocą
GOSUBiRETURNstamtąd) – brak funkcji, procedur, wszystkie zmienne były globalne. - W latach 70. nie miał nawet instrukcji
IF ... THEN ... END IF– musiałeś przejść do linii (jak przy użyciuGOTO), jeśli warunek był spełniony, jak w języku asemblera. - W momencie, gdy był tak głośno krytykowany, nie obsługiwał żadnego wprowadzania danych przez użytkownika, nie miał wsparcia dla grafiki i dźwięku – ponieważ i tak nie było monitora ani głośnika.
- Po zdobyciu tego wsparcia, nie został on ustandaryzowany, nie wszystkie komputery miały równy dostęp do swoich własnych możliwości z BASICa (przykro mi, C64, nie ma dla ciebie
PLOTowania punktu czy rysowania linii dziękiLINE), wiele słów kluczowych i ich zachowanie różniło się między implementacjami. - BASIC, którego krytykował Dijkstra był językiem kompilowanym. A jeśli sięgamy po język kompilownay, to był już też PL/I ze wszystkimi procedurami, lokalnymi zmiennymi i wsparciem struktur.
- Brak struktury kodu (z wyjątkiem możliwości skoku do linii kodu za pomocą
- Ale miał też swoje zalety:
- Był na tyle prosty, że każdy początkujący mógł tworzyć programy uniwersalnego zastosowania (BASIC to skrót od Beginners All Purpose Symbolic Instruction Code). Wystarczy nauczyć się kilku słów kluczowych sterujących i gotowe – opanowałeś sam język.
- Gdy w latach 80. pojawiły się komputery domowe, umożliwiał on szeroki dostęp do możliwości komputera – dyskietek, kaset, grafiki, dźwięku, bezpośredni dostęp do pamięci i sprzętu (ok, nie zagłębiałem się jeszcze zbyt głęboko w te funkcje w dotychczasowych postach)!
- Dzięki swojej prostocie, uczył użytkowników, jak komputer działa wewnętrznie. Inne języki ukrywają mechanikę współdziałania procesora i pamięci pod wieloma poziomami abstrakcji, ale gdy ich nie ma, odkrywasz te podstawy i uczysz się ich sam(a). Instrukcje
GOTOiGOSUBto tak naprawdę te same skoki, jakie wykonuje wewnętrznie procesor komputera. Jeśli twoje zmienne nie mają żadnej struktury w pamięci, musisz sam zrozumieć, jak nimi zarządzać.
Ten, który wchodził na uczelnie – Pascal
W tytule jest wspomniany Pascal – ponieważ język ten został opublikowany przez Niklausa Wirtha “około 1970 roku”, więc mógł być czymś do porównania z BASICiem. Jednak, aby być historycznie poprawnym, także nie został wtedy stworzony od podstaw. Pascal był luźno oparty na Algolu 60, który istniał od lat 60. Algol 60 może wyglądać trochę znajomo, nawet jeśli nazwa nie jest (przykładowe źródło: wikipedia):
procedure Absmax(a) Size:(n, m) Result:(y) Subscripts:(i, k);
value n, m; array a; integer n, m, i, k; real y;
comment Najwięksa wartość absolutna w macierzy a o rozmiarze n na m,
jest kopiowany do y, a indeksy tego elementu do i i k;
begin
integer p, q;
y := 0; i := k := 1;
for p := 1 step 1 until n do
for q := 1 step 1 until m do
if abs(a[p, q]) > y then
begin y := abs(a[p, q]);
i := p; k := q
end
end Absmax
W latach 70. Pascal stawał się popularny na rynku “minikomputerów”. Jeśli pamiętasz, że komputer był ogromnym zdalnym mainframe’em, możesz się domyślić, że minikomputer to taki, który jest mniejszy niż pokój, w którym stoi, mający może jakieś 2 metry wysokości i metr szerokości. I ma wbudowane magnetofony szpulowe.
Począwszy od lat 80., a z całą pewnością przez całe lata 2000., Pascala można było doświadczyć na uniwersytetach. “Podobnie jak BASIC” – mogą pamiętać niektórzy z poprzedniego artykułu. Ale Pascal mógł służyć głębszemu celowi niż BASIC – zamiast uczyć się, jak kodować, mogłeś teraz nauczyć się, jak projektować algorytmy i struktury danych. Jest to często przedmiot pod tą samą nazwą na wielu kierunkach Informatyki, ale też tytuł książki Niklausa Wirtha (twórcy Pascala) z 1985 roku (niektóre wydania także pod tytułem “Algorytmy + Struktury Danych = Programy”).
Wspomnijmy jeszcze raz o Edsgerze Dijkstra. W 1960 roku opublikował artykuł zatytułowany “Programowanie rekurencyjne“, definiujący to, co przez następne 64 lata nazywaliśmy “stosem” (jak w “stosie wywołań”, ale także “stosie vs stercie” – dwóch głównych sposobach przechowywania zmiennych w programach komputerowych także dzisiaj). Jak zauważono we wstępie do “algorytmów i struktur danych”, Dijkstra był również autorem publikacji zatytułowanej “Notatki o programowaniu strukturalnym” (1970), która ukształtowała programowanie strukturalne na wiele dekad, jeśli nie dosłownie wieki. W tej publikacji, Dijkstra prezentuje fundamentalne koncepcje i zasady tworzenia przejrzystych, niezawodnych i efektywnych programów komputerowych. Techniki i idee przedstawione w tym artykule wywarły trwały wpływ na rozwój metod programowania i przyczyniły się do ustanowienia najlepszych praktyk w zakresie projektowania i rozwoju oprogramowania.
Programowanie strukturalne to paradygmat programowania mający na celu poprawienie klarowności, jakości i czasu wdrażania programu komputerowego poprzez intensywne wykorzystanie podprogramów, struktur blokowych, pętli for i while oraz innych struktur sterujących. Promuje ideę podziału programu na małe, “ogarnialne” sekcje, co ułatwia jego zrozumienie i utrzymanie.
Daje nam to tło, na którym urodził się Pascal (język! :D), jak go uczono, i jak pomógł rozpowszechnić dobre praktyki wprowadzania odpowiedniego poziomu abstrakcji w kodzie i w danych. W Algorytmach i strukturach danych możemy znaleźć opisy najczęstszych problemów do rozwiązania w dowolnym programie komputerowym, zilustrowane przykładami kodu w Pascalu:

Powyższy przykład z książki opisuje algorytm sortowania MergeSort w sposób akademicko zwięzły, prawdopodobnie nie najbardziej przyjazny dla czytelnika. Uwierz mi, używanie czcionki o stałej szerokości dla kodu komputerowego nie było jeszcze modne, zwłaszcza w poważnych publikacjach, a kolorowanie składni to już w ogóle kaprys z ery komputerów PC.
Czemu to robiło różnicę?
Szeroka popularność Pascal’a miała pewne zalety. Został on zaprojektowany, aby kod był bardziej zrozumiały – zarówno dla człowieka, jak i komputera.
Człowiek mógł skorzystać na zamknięciu bardziej złożonej logiki w procedurach lub funkcjach (w tym rozróżnieniu, funkcja to procedura zwracająca wartość), które można wywoływać z innych miejsc w kodzie, tak jak robimy to we wszystkich nowoczesnych językach programowania. Na przykład wywołując padWithZeroes('123'). Kod mógł być zorganizowany i sformatowany w sposób bardziej zrozumiały dla człowieka, szczególnie dzięki blokom zagnieżdżonym zarówno logicznie, jak i wizualnie (auć, tyle bajtów pamięci na spacje i tabulatory!).
Język zachęcał do definiowania własnych typów i podtypów dla wszystkiego – co jest bardzo dobrą praktyką. Na przykład (z wielkimi literami nadal będącymi najczęściej stosowanym zapisem dla wielu rzeczy, przy czym Pascal nie rozróżniał wielkości liter):
TYPE
COLOR = (RED, YELLOW, BLUE, GREEN, ORANGE);
SCORE = (LOST, TIED, WON);
SKILL = (BEGINNER, NOVICE, ADVANCED, EXPERT, WIZARD);
PRIMARY = RED .. BLUE;
NUMERAL = '0' .. '9';
INDEX = 1 .. 100;W tym przykładzie, kiedy tworzymy podtyp, jak na przykład NUMERAL, klaruje to zarówno dla czytającego kod, jak i dla kompilatora, że dozwolone są tylko określone wartości. Podobnie, typ COLOR byłby wyliczeniem, dzisiaj czesto definiowanym za pomocą słowa kluczowego enum, określającym zakres potencjalnych literałów. To podejście informuje nie tylko programistów, czego się spodziewać podczas czytania kodu, ale również umożliwia kompilatorowi zabronienie niewłaściwego użycia i przypisywania nieodpowiednich wartości i wykonywania operacji, które nie mają sensu dla danego typu. Dodatkowo kompilator znając zakres wartości mógłby zdecydować o użyciu do ich reprezentacji mniejszego kawałka pamięci.
To, że Pascal był językiem kompilowanym oznaczało także, że oprogramowanie napisane w nim wykonywało się szybciej niż napisane w języku interpretowanym – ponieważ w momencie wykonania cały program jest już kodem maszynowym, gotowym do wykonania bez dodatkowych kroków. Oznaczało to również trudność w sprawdzeniu, jak działa on wewnętrznie i trudność w modyfikowaniu go – cechy zazwyczaj pożądane przez twórców oprogramowania komercyjnego.
Zanim przejdziemy do ostatniej korzyści: sprecyzujmy różnicę między dwoma podobnymi pojęciami w kodzie: deklaracja vs definicja.
W wielu nowoczesnych językach pomija się deklaracje, co sprawia, że trudniej jest zauważyć różnicę. W istocie, deklarując funkcję lub zmienną, informujemy kompilator tylko o tym, że istnieje — gdzieś tam i jak wygląda, ale jeszcze nie zajmujemy dla niej ani jednego bajta.
Definicja funkcji natomiast zawierałaby faktycznie kod wymagany do jej zaimplementowania lub, w przypadku zmiennych, dane, które mają być z nimi powiązane.
Na przykład deklaracja procedury hello world w Pascalu wyglądałaby tak:procedure SayHello;
a deklaracja zmiennej mogłaby wyglądać tak: var a: Integer;, zazwyczaj grupowana z innymi zmiennymi w bloku var, który deklaruje wszystkie zmienne, które będą używane w kolejnym bloku kodu.
podczas gdy definicja tej funkcji wyglądałaby tak:procedure SayHello;
begin
WriteLn('Hello, world!');
end;
definiowanie zmiennej nastąpiłoby, gdy faktycznie przypiszemy do niej wartość:a := 10;
Pascal jest zaprojektowany tak, aby umożliwić szybką kompilację, nawet na małych maszynach, i aby była ona zakończona w jednym przejściu poprzez plik źródłowy. Wprowadziło to wymóg deklarowania wszystkich zmiennych przed użyciem w każdym bloku, a także deklarowania każdej procedury przed jej wywołaniem, co może być uważane za niewygodne i przestarzałe w nowoczesnych praktykach programowania. Jednak pozwoliło to uprościć i przyspieszyć kompilację, zmniejszyć zużycie pamięci i zachęcić programistów do bardziej systematycznego organizowania swojego kodu.
Choć może to być niewygodne w przypadku dużych funkcji, deklarowanie zmiennych blisko miejsca, w którym będą używane (jak jest to preferowane dzisiaj) nie było priorytetem i zostało poświęcone by osiągnąć te cele optymalizacji.
Największą zaletą Pascala, zarówno nauczanego, jak i popularnego w każdym rodzaju programowania, było to, że dostępne było – i nadal jest – wiele źródeł do czytania na jego temat, wiele przykładów i kodu referencyjnego.
Lubię być praktyczny, gdzie mogę *używać* Pascala?
Świetnie, że pytasz! Załóżmy na razie, że jesteśmy w latach 80. Odpowiedź brzmi wszędzie. Chociaż wariant UCSD Pascal powstały na Uniwersytecie Kalifornijskim w San Diego przestawał być wzorcowym i głównym (stworzony w 1977, ostatnie wydanie w 1984), większość komputerów miała jakąś wersję Pascala. Amstrad CPC464 i ZX Spectrum miały HiSoft Pascal, Atari miało Kyan Pascal, Commodore miało Pascal-64, a użytkownicy Macintosha pamiętają Lightspeed Pascal.
Oczywiście nie chcemy umniejszać znaczenia UCSD Pascal, ponieważ działał na wielu komputerach (łącznie z takimi dużymi jak PDP-11 :)), oraz mikrokomputerach z najpopularniejszymi procesorami: Intel 8080, Zilog Z80, MOS 6502, Motorola 68000… Możliwość dzielenia się kodem dla tego samego dialektu miała znaczenie. Co prowadzi nas do pewnego Pascala dla CP/M…
Dzięki popularności systemu CP/M, który mógł być współdzielony przez prawie wszystko, co było zbudowane z procesorem Z80, każdy komputer, który mógł go uruchomić (Amstrad CPC, Spectrum +3, C128, Apple II z kartą Z80, MSX, IBM, Sam Coupe, TRS-80, i wiele innych), mógł również uruchomić najpopularniejszą wersję tego języka – Turbo Pascal firmy Borland (most known from the later editions for the IBM PC compatibles).
Powyżej widzimy zapis ekranu Turbo Pascala 3.0 działającego pod systemem operacyjnym CP/M na Amstradzie CPC 6128 – maszynie z procesorem Z80 o taktowaniu 4 MHz (w praktyce “około 3.3 Mhz”) i 128 KiB RAM. Wspomniane 128KiB pamięci RAM jest tu wystarczające do przechowywania systemu operacyjnego, kompilatora i edytora, kodu źródłowego oraz programu, który jest kompilowany, a także zawartości całego ekranu. Możesz zauważyć, że każdy bajt wyprodukowanego kodu jest starannie zliczany, a my nadal mieliśmy ponad 28KiB wolnej pamięci.
Ten konkretny kompilator Pascal stał się tak popularny, że wiele osób myli go z nazwą języka (przez ostatnie 40 lat). Narzędzie i język ewoluowały razem, wraz z sprzętem, na którym mogły działać. Choć nie ma nowszej wersji dla systemu CP/M niż 3.0, niektóre późniejsze wersje przyniosły znaczne ulepszenia:
- v4.0 wprowadził jednostki (
units), ułatwiając tworzenie jeszcze bardziej modularnego kodu, gdzie każda jednostka mogła być kompilowana oddzielnie. Wprowadził także pełnoekranowy edytor, który był tak bardzo lubiany; to jedno z pierwszych środowisk IDE (Integrated Development Environments), które kiedykolwiek istniały, gdzie jeden pełnoekranowy interfejs pozwalał na edycję kodu, kompilację i debugowanie go.
W wersji 5.0 stał się kolorowy, z dobrze znanym połączeniem niebieskiego, białego i żółtego:
(zdjęcie dzięki uprzejmości Adama Cichowicza z jego filmu na YT o TP 5.0) - v5.5 wprowadził programowanie zorientowane obiektowo – od teraz można było korzystać z klas, które od 1989 roku są głównym sposobem enkapsulacji naszej logiki biznesowej, którego tylko JavaScript i Golang nie chcą przyjąć ;-).
Klasa to mniej więcej to, co sugeruje nazwa – jest produktem klasyfikacji idei opisujących świat wokół nas do hierarchii kategorii. Klasa obiektów dzieli pewne właściwości – mogą mieć ten sam zestaw atrybutów lub funkcjonalności. Najbardziej standardowy przykład: możemy wyodrębnić klasęZwierzęspośród wszystkim obiektów, które mogą mieć podklasy, takie jakPies,Kotczy, co może stanowić szok dla niektórych (uwaga: link do TikTok),Człowiek. Możemy powiedzieć, że każde zwierzę “implementuje” (realizuje funkcjonalność)JedziŚpij, ale tylkoPiesmoże wykonaćSzczekaj.
Można powiedzieć, żePiesiKotsą podklasamiZwierzęi dziedziczą one po tej klasie (czyli własność klasy nadrzędnej jest również własnością klasy podrzędnej).
Tylko trochę żartuję tutaj o JS i Golang. Większość głównych języków obsługuje klasy. JavaScript realizuje programowanie zorientowane obiektowo trochę inaczej – tak zwane dziedziczenie jest oparte bezpośrednio na instancjach obiektów, a nie na klasie. GoLang udaje, że nie ma klas, ale ma struktury danych, które mogą mieć metody, przepraszam, funkcje do nich dołączone… co w zasadzie jest tym samym. - Turbo Pascal 7.0 wprowadził podświetlanie składni w 1992 roku. Była to także ostatnia wersja interfejsu opartego na tekście, później zastąpiona już przez Turbo Pascal for Windows, a później Delphi.
- Użytkownicy Macintosha cieszyli się swoim Turbo Pascal dla Macintosha 6 lat wcześniej, w 1986 roku! Winworld pisze o nim: “Turbo Pascal dla Macintosha to krótko wspierana wersja produktu Pascal od Borlanda na Apple Macintosh. Charakteryzował się bardziej zaawansowanym kompilatorem niż wersja DOS w tym czasie. To były niewygodne czasy, ponieważ Borland wcześniej ostro krytykował niedopracowaną i zamkniętą architekturę Macintosha 128k, podczas gdy w tym samym czasie Apple nie było zbyt przyjazne dla narzędzi deweloperskich firm trzecich.”
Mimo że technicznie nie jest już Turbo Pascalem i nie pojawił się do 1995 roku, nadal to Pascal – więc na pewno powinienem wspomnieć o Delphi. To był ogromny skok od pisania w Pascalu dla DOS-a lub Windowsa (co wymagało wiedzy o tym, jak działa Windows, jak są renderowane okna i przyciski i jak komunikować się z systemem operacyjnym), do możliwości bardzo łatwego tworzenia aplikacji – wystarczyło upuścić przycisk na okno i kliknąć go dwukrotnie, aby napisać kod, który zostanie wykonany po jego kliknięciu. Szczerze mówiąc, często nawet dzisiaj nie jest to takie proste.
Kilku-okienkowy interfejs Delphi cieszył się ogromną popularnością i stał się sam w sobie standardem, mimo że nie była to pierwsza aplikacja, która go posiadała – był on mocno inspirowany… Visual Basicem z 1991 roku! Niemniej jednak, dla wielu programistów, lekka “ostatnia naprawdę szybka wersja” Delphi 7 pozostała w użyciu nawet 20 lat po jej wydaniu (src).
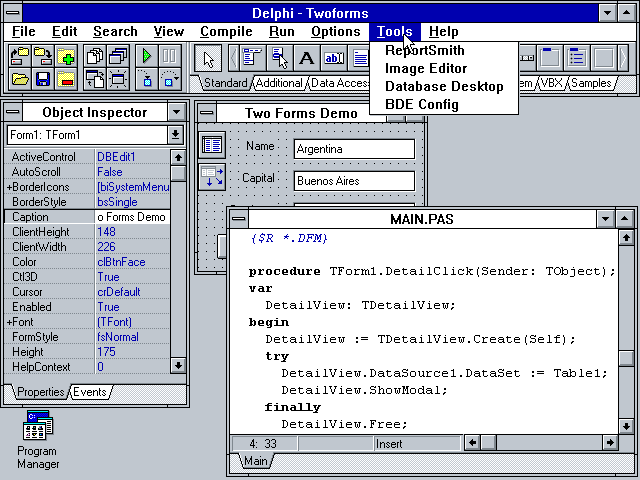
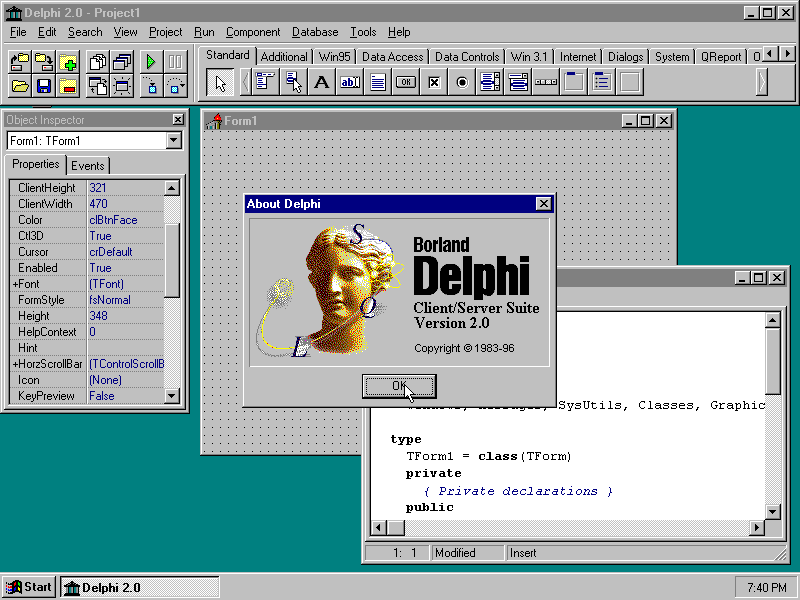
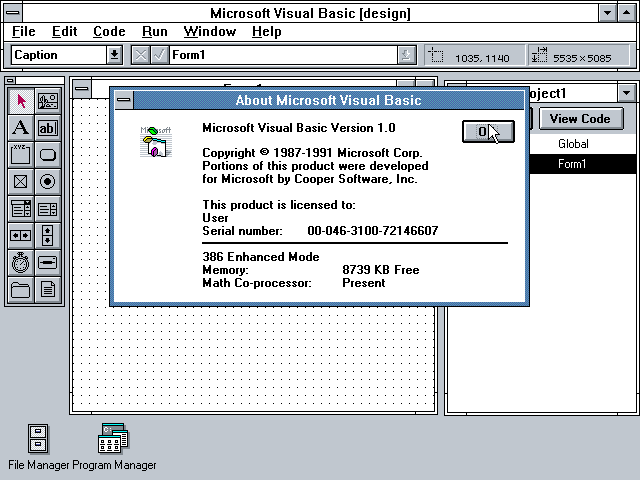
C jak class (klasa)
No, tyle że język C nie obsługuje klas (przypomnienie: C i C++ to nie te same języki). Nazwa tak naprawdę oznaczała następstwo dla języka B stworzonego w Bell Labs w 1969 roku.
Ale język istniał w latach 70. (w pewnym sensie) i w latach 80.! Był w trakcie rozwoju (pierwsza książka dokumentująca go została opublikowana w 1978 roku i odnosi się do Fortrana i Pascala), i jeszcze nie był prawdziwą alternatywą dla BASIC-a, kiedy znany informatyk krytykował BASIC-a, COBOL-a, Fortrana i APL-a. Może dlatego go nie skrytykował.
Pierwotne projekty C i Pascala były skierowane na realizację różnych celów. C początkowo zostało opracowane do implementacji systemu operacyjnego Unix, ze szczególnym naciskiem na dostęp na niskim poziomie do pamięci i zasobów systemowych, dzięki czemu doskonale nadawało się do programowania systemowego i tworzenia systemów operacyjnych. Z kolei Pascal został zaprojektowany jako język do nauczania programowania i zasad inżynierii oprogramowania, z dużym naciskiem na czytelność, strukturalne programowanie i strukturyzowanie danych.
Ta różnica jest widoczna w tym, jakie oba języki sprawiają wrażenie i na co kładą nacisk. Zwykle C jest “bliżej metalu” – na przykład nie ma rozróżnienia między typem char, który reprezentuje pojedynczy znak, a short int. C doskonale radzi sobie z wyrażeniami takimi jak int x = 'b'-1 czy char c = 64. Jest to zgodne ze sposobem działania procesora – znak był zwykle pojedynczym bajtem, często przechowywanym w rejestrze jednobajtowym gdy z nim pracowaliśmy, i dla komputera nie ma znaczenia, co on reprezentuje. Pascal dąży do abstrahowania różnych znaczeń w różne typy, więc mimo że dla procesora nie ma znaczenia, czy jest to 'a' czy liczba 97, programista powinien wyraźnie i jednoznacznie używać ord('a'), aby przekonwertować literę na kod ASCII, lub chr(97), aby przekonwertować go z powrotem.
Najbardziej praktyczne zastosowanie tej cechy C to konwersja cyfry na jej wartość za pomocą val = digit - '0'; – odejmowanie kodu ASCII znaku 0 od znaku wejściowego.
Podobnie, wiemy, że komputery operują na 0 i 1, tak zwanych wartościach binarnych (binarnych, bo są tylko dwie), reprezentujących prawdę i fałsz pewnej informacji. Pascal zgodnie z tym definiuje true i false jako dwie wartości wyliczeniowe dla typu boolean, podczas gdy C… decyduje, że nie ma typu bool, a wszystko co istnieje, to 1 i 0. Pozostaje to w mocy nawet dla wartości operacji, takich jak porównanie a == b – z technicznego punktu widzenia w C zwraca ono 1 lub 0, a nie true lub false. To również wydaje się bliskie maszynie, na której działa.
W tamtym czasie powszechną konwencją w asemblerze było przekazywanie wartości zwrotnej w rejestrze A (dla 8-bit, później AX dla 16-bit, i EAX dla 32-bit) procesora.
(Dlaczego? Jednym z powodów jest to, że jest to szybsze niż zwracanie przez wartość w pamięci na większości architektur, nawet z tego okresu, a w późniejszych latach przekazywanie wartości zwrotnych w rejestrach, a nie w pamięci, pozwalało na bezpieczniejsze i bardziej przewidywalne wykonywanie funkcji, szczególnie w scenariuszach, w których funkcje mogły być przerywane i wywoływane ponownie przed ukończeniem poprzednich wywołań – a wszystkie wartości rejestrów są przywracane po wznowieniu z przerwania).
Pierwsza wersja C nawet nie wymagała określenia typu zwracanej przez funkcję wartości, tylko zakładała, że to jest int! Dla twórców Pascla byłoby to szkodliwe, zresztą także dzisiaj nieokreślanie typu zwracanego jest uważane za złą praktykę w C.
Sprawdźmy kilka bardzo podstawowych przykładów (bez struktur danych):
/* Przykład w C z 1978 do sprawdzenia, czy ciąg znaków jest palindromem */
#include <stdio.h>
#include <string.h>
isPalindrome(char *str) {
int len;
int i, j;
len = strlen(str);
for (i = 0, j = len - 1; i < j; i++, j--) {
if (str[i] != str[j]) {
return 0; /* Nie jest palindromem */
}
}
return 1; /* Jest palindromem */
}
main() {
char testStr[];
testStr = "radar";
if (isPalindrome(testStr)) {
printf("%s jest palindromem\n", testStr);
} else {
printf("%s nie jest palindromem\n", testStr);
}
return 0;
}natomiast w Pascalu mielibyśmy:
(* Pascal, sprawdzanie czy ciąg jest palindromem *)
program PalindromeCheck;
function IsPalindrome(str: string): Boolean;
var
i, j: Integer;
begin
j := Length(str);
for i := 1 to j div 2 do
begin
if str[i] <> str[j - i + 1] then
begin
IsPalindrome := False; { Nie jest palindromem }
Exit;
end;
end;
IsPalindrome := True; { Jest palindromem }
end;
var
testStr: string;
begin
testStr := 'radar';
if IsPalindrome(testStr) then
writeln(testStr, ' jest palindromem')
else
writeln(testStr, ' nie jest palindromem');
end.Można zauważyć, że C nie przesadza z używaniem zbyt wielu typów danych – na przykład tam, gdzie Pascal ma typ string, C używa wskaźnika do znaku. Zakłada się, że kolejne znaki podążają zaraz za tym wskaźnikiem, a łańcuch kończy się tam, gdzie znajduje się bajt 00 (tak zwany łańcuch null-terminated). Przykład pokazuje również, że char * jest w zasadzie tym samym, co tablica znaków – testowy łańcuch jest zadeklarowany jako tablica. Zwracamy także wartość całkowitą zamiast wartości boolean, nie podając w ogóle jej typu.
W Pascalu funkcje mają tę interesującą konwencję, która nie przyjęła się w wielu językach, że można przypisać wartość wyniku do nazwy funkcji. Więc kiedy wykonamy IsPalindrome := False;, wartość ta stanie się wynikiem danego wywołania IsPalindrome, chyba że zostanie zmieniona później, przed wyjściem z funkcji.
Podczas gdy oba języki w tamtym okresie rozdzielają deklaracje zmiennych i ich użycie, C miał tę miłą cechę, że możliwe było zainicjowanie zmiennej wartością w jej deklaracji (int l = strlen(s). Oryginalny Pascal tego nie obsługiwał (ale na przykład dzisiejszy Free Pascal już tak). Natomiast pakiet stdio w C zapewniał nadzwyczaj przydatną funkcję printf, gdzie f oznacza “format” – można zadeklarować całą postać wiadomości na początku, a osobno argumenty, które mają być do niej wstawione. Sprawia to, że czytanie kodu formatującego łańcuchy tekstowe staje się o wiele łatwiejsze.
Warto również wiedzieć, że C powstało głównie na maszynach 16-bitowych, które istniały w latach 80-tych, ale nie były to te, które można było znaleźć w domu. Dlatego zwykły użytkownik komputera domowego, nawet jeżeli chciałby zainteresować się kompilowanymi językami, prawdopodobnie nie traktowałby tego języka jako dostepnej i popularnej opcji.
Do dnia dzisiejszego, kierowanie do maszyn 8-bitowych w C jest uważane za nieoptymalne, a także wiele optymalizacji tam nie funkcjonuje.
C jak Ciągła zmiana
Dzisiaj, gdy mówisz “jest napisane w C”, to nie jest ten sam język, którego używaliby Ritchie i Kernighan. Szczerze mówiąc, to co sugerował ich standard, często nie jest dozwolone przez kompilatory używane dzisiaj.
Podobnie jak wiele języków, C zostało ustandaryzowane, a także ewoluowało. Pierwsza większa zmiana przyszła z normą ANSI C (C89), która została ukończona w 1989 roku i zatwierdzona jako ANSI X3.159-1989. Ta wersja języka często jest określana jako “ANSI C”, lub C89, i wprowadziła znaczące zmiany do języka, takie jak słowa kluczowe volatile, enum, signed, void, i… const.
Późniejsze standardy, w tym C99 i C11, wprowadziły dalsze modyfikacje języka, rozwijając jego możliwości, składnię i semantykę.
Niektóre zmiany zostały zaadaptowane z języka, który miał na celu być ulepszeniem w stosunku do C, czyli z C++: programiści wreszcie mogli swobodnie deklarować funkcje w dowolnym miejscu kodu (mieszać deklaracje z wykonywanymi instrukcjami), ponieważ kompilator miał teraz do dyspozycji dużo więcej pamięci, a C99 w końcu dodał typ bool do języka! Inną przeniesioną funkcją, której można by się spodziewać, że już dawno była dostępna, była możliwość używania komentarzy “od teraz do końca linii”, czyli: // komentarz.
Pascal vs C – podsumowanie
Większość innych funkcjonalności C ma na celu przede wszystkim ułatwienie pisania – wiele skrótów, skrótów, krótszych i mniej rozwlekłych operatorów (jak i++ zamiast i = i+1), mieszanie typów, które są reprezentowane identycznie wewnętrznie przez CPU.
Chociaż C jest super zwięzłe, ta sama sekwencja znaków może oznaczać różne rzeczy w zależności od kontekstu, na przykład a * b może oznaczać zarówno “pomnóż a przez b” jeśli jest to wyrażenie (jak wynik = a*b), lub “a jest wskaźnikiem do zmiennej typu b” (częściej zapisywane jako a *b), jeśli jest to deklaracja zmiennej lub argumentu.
Pascal poszedł w inną stronę, starając się, aby kod był łatwy do czytania bez potrzeby analizowania go zbytnio. Struktura kodu była wyraźnie widoczna, zalecano, by typy były definiowane jako jak najbliższe ich właściwemu (logicznemu, biznesowemu) znaczeniu.
Oba wyrażenia z powyższego przykładu a*b są w nim jednoznaczne: albo to mnożenie napisane jako wynik := a*b; albo zmienna jest wskaźnikiem, deklarowanym jako var a ^b; – zarówno człowiek, jak i kompilator jednoprzebiegowy nie muszą sprawdzać niczego innego.
Wygląda więc na to, że po 8 latach używania Pascal’a, pojawiła się potrzeba szybszego pisania kodu 😉 używając mniejszej liczby znaków. Jeżeli chcesz poznać więcej różnic, na Wikipedii jest cały artykuł porównujący oba języki wiele aspektów.
Podczas gdy języki te ułatwiają pisanie bardziej zorganizowanych programów, najbardziej wydajne dla maszyn 8-bitowych były, i często nadal są, pisane bezpośrednio w asemblerze. Użytkownik retrac w jednym z komentarzy ma ciekawe spostrzeżenia na ten temat:
Języki takie jak C i Pascal zastrzegają sobie korzystanie z wygodnego, taniego stosu. Klasycznie, wywołanie funkcji oznacza wrzucanie wszystkich parametrów na stos, a następnie adresu powrotu, skakanie do funkcji, ściąganie wszystkich parametrów ze stosu, wrzucanie wartości zwracanej na stos, modyfikację wskaźnika stosu by pozbyć się parametrów, a potem odczytanie adresu powrotu z tego stosu.
Ani Z80 ani 6502 nie mają instrukcji, które zapewniają efektywny stos, który obsługuje dane wielobajtowe. Ciągle musisz manipulować wskaźnikiem stosu (zazwyczaj dla stosu implementowanego programowo) za pomocą powolnej, 8-bitowej arytmetyki. Bolesne.
Zestaw instrukcji PDP-11, w porównaniu, zapewnia nie jeden, ale aż siedem, elastycznych 16-bitowych stosów.
Forth (naprzód!)
Inny język nie wymieniony w wpisie “Czy BASIC był tak straszny…” który faktycznie miał ogromne znaczenie w tej erze komputeryzacji, to Forth.
: isPalindrome ( addr -- flag )
dup >r \ Powiela adres i przenosi jedną kopię do stosu powrotów
bounds ?do \ Iteruje po stringu
i c@ r@ - \ Oblicza adres odpowiadającego znaku od końca
dup i c@ <> if \ Porównuje znaki
drop r> drop false exit \ To nie jest palindrom, sprząta i zwraca false
then
loop
drop r> drop true \ To jest palindrom, sprząta i zwraca prawdę
;
Jak widać, jest znacznie odmienny od wszystkich języków omawianych w tym i poprzednim wpisie. Nie jestem ekspertem od Fortha. Mogę natomiast wskazać główne różnice i powiedzieć, dlaczego używanie go miało sens. Podzielę się również linkami do dalszej lektury dla ciekawskich.
Przede wszystkim, w przeciwieństwie do strukturalnego podejścia Pascal’a i proceduralnego paradygmatu C, Forth oferuje inny model programowania – oparty na wykonaniu zorientowanym na stos i minimalistycznej składni. Oznacza to, że argumenty dla każdej operacji były wrzucane na stos (ten sam stos, z którego pobieramy adres RETURN, opisany w dokumencie Recursive Programming). Samą operację podajemy jako ostatnią część wyrażenia. Prosta operacja taka jak: 1 + 2
zostanie więc zapisana jako: 1 2 +.
Nazywamy to “Odwrotną Notacją Polską” lub “odwrotną notacją Łukasiewicza“. Pozwala ona by kompilator (lub interpreter) mógł przechodzić przez kod słowo po słowie, nie mając pamięci ani oczekiwań, patrząc na kolejne elementy: “czy to jest polecenie? nie? w takim razie wrzućmy to na stos. A to? Wykonaj to, a to sobie już pobierze argumenty ze stosu”.
Cytując “Zgubiony przy C? Może odpowiedzią jest Forth“:
Gdy piszesz C = A + B, kompilator odkłada operacje “równości” i “plus” na swoją listę oczekujących, aż dojdzie do końca wyrażenia. Potem przepisuje to jako “Weź A, Weź B, Dodaj, Zapisz C”.
Forth pomija ten środkowy krok. W Forth, piszesz tę samą operację jako: A @ B @ + C !. @ i ! to skróty notacji Forth’a dla operacji “fetch” i “store”. + , jak się domyślasz, reprezentuje dodawanie.
Oznacza to, że Forth jest wyjątkowo efektywny pod względem pamięci i CPU – a przecież pamiętajmy, że procesory były wolniejsze a pamięć bardzo droga w tamtych czasach. Dlatego możemy znaleźć w cytowanym wyżej dokumencie zdanie wskazujące na coś, co dzisiaj uważalibyśmy za oczywiste:
Często można rozwijać program Forth bezpośrednio na docelowym systemie.
http://www.forth.org/lost-at-c.html?locale=en
Nie zawsze było tak łatwo rozwijać program i uruchamiać go na tym samym urządzeniu. Spowodowane to było nie tylko problemami już wymienionymi (takimi jak uciążliwe przełączanie się między edytorem, kompilatorem i stworzonym programem), ale również ograniczeniami technicznymi. Kompilacja oprogramowania wymaga załadowania do pamięci znacznie większej ilości danych, niż będzie zawierać wynikowy program. Chociażby dlatego, że kod źródłowy ma więcej bajtów od skompilowanego programu (co jest jedną linią kodu dla człowieka, może być trzema bajtami dla docelowej maszyny). Dodatkowo, aby rozwiązać wszystkie odwołania (takie jak nazwy zmiennych, funkcji i typów), wszystkie muszą zmieścić się w pamięci i musi dać się je przeszukać w rozsądnym czasie.
Z tego samego powodu, jeżeli chcesz dzisiaj programować dla systemu CP/M, Amstrada, Apple II, Commodore 64, albo ZX Spectrum (i tak dalej…), najprawdopodobniej spróbujesz kompilacji krzyżowej (i zapewe użyjesz C) – piszesz kod na bardziej wydajnym i zasobnym PC, a tylko uruchamiasz go na platformie docelowej. A i to pewnie po testach z emulatorem.
Na koniec, wracając do języka – Forth pozwala również na definiowanie własnych słów kluczowych, a ta elastyczność umożliwia programistom tworzenie innych, zazwyczaj specyficznych dla dziedziny języków i dostosowanie go do konkretnych aplikacji.
Czy nadal jest używany? Tak!
Forth nadal jest używany przez IBM, Apple i Sun. Jest używany do sterowników urządzeń, zwłaszcza podczas bootowania systemu operacyjnego. FORTH jest bardzo przydatny na mikrokontrolerach, ponieważ zużywa bardzo mało pamięci, może być szybki, a pisanie kodu jest łatwiejsze niż w assemblerze, nawet w trybie interaktywnym.
https://stackoverflow.com/questions/2147952/is-forth-still-in-use-if-so-how-and-where
Dzisiaj
Najczęstszym pytaniem, które należy tutaj zadać, byłoby “czy i dlaczego C i Pascal nie są dziś używane?”.
Odpowiedź, jeśli sprawdzimy bez uprzedzeń, brzmi “są używane”.
Na podstawie niedawnych i bardzo współczesnych dyskusji i zmian, wydaje się, że rośnie tendencja do rozważania zastąpienia C i C++ przez Rust w pewnych dziedzinach. Rust jest doceniany za skupienie na wydajności i bezpieczeństwie, które są obszarami, gdzie rodzina C zawsze stawiała na szybkość kosztem bezpieczeństwa. Niektóre źródła sugerują, że Rust zdobywa na popularności i może potencjalnie zastąpić też C++ w pewnych aplikacjach, ale ważne jest, aby zauważyć, że C (bez ++) wciąż jest aktywnie używane w wielu obszarach, zwłaszcza w “sprzętowym” programowaniu, gdzie kluczowe jest precyzyjne kontrolowanie operacji i zarządzanie pamięcią.
Jądro systemu Linux jest napisane w języku programowania C. W najbliższej przyszłości, jednak prawdopodobnie coraz więcej elementów Linuxa i jądra Windowsa będzie przepisywanych na Rust.
Chociaż może nie jest tak powszechny w nowoczesnym rozwoju oprogramowania w porównaniu do języków takich jak Python, Java, czy C++, Pascal miał znaczący wpływ i nadal jest używany w pewnych obszarach, więc nie zniknął całkowicie z pejzażu programowania. Jednak nie dostosowuje się zbyt szybko do wciąż zmieniającej się konkurencji i nie pojawiają się w nim nowe, konkurencyjne (ani goniące konkurencję) funckjonalności. Nie jest to w każdym razie temat newsów branżowych.
Język Object Pascal został przemianowany na Delphi – Delphi nadal jest drogim komercyjnym narzędziem do szybkiego tworzenia aplikacji. Umożliwia ono pisanie kodu zarówno dla komputerów osobistych, jak i urządzeń mobilnych, a także aplikacji wieloplatformowych (Windows, macOS, Linux, iOS i Android) za pomocą ich silnika FireMonkey.
Istnieje darmowa wersja Delphi Community Edition.
Moim zdaniem, to jest jedna z największych krzywd, jakie spotkały ten język – stał się zbyt związany z jedną firmą.
Moim zdaniem, to jest jeden z największych szkód, które spotkały ten język – stał się zbyt kojarzony z jednym, szczególnym producentem, z własnościowym IDE i wygórowaną ceną, co zabiło jego popularność.
Odkąd pamiętam, zakup licencji na Delphi kosztował 3-5x więcej niż zakup podobnej licencji na Visual Studio – a to jeszcze zanim pojawiło się bezpłatne Visual Studio Express, nie mówiąc o otwartym Visual Studio Code (github).
Najbardziej popularny Pascal był historycznie rozwijany przez Borland (która później zmieniła swoją nazwę na Inprise). Następnie był własnością Embarcadero Technologies, obecnego właściciela Delphi. Darmowe alternatywy takie jak Free Pascal (jest to również nazwa języka; Free Pascal pozostaje wolny) lub IDE dla niego, Lazarus, wspomniane poniżej, próbują nadganiać, ale trudno jest dorównać komercyjnej skali, prędkości rozwoju i rynkowi, jakim dysponuje dobrze finansowany projekt jakim jest/był Delphi.
Dlatego Free Pascal i Lazarus są nadal mają się dobrze, ale nie ewoluują szybciej ani dalej niż komercyjne Delphi.
Castle Game Engine jest napisany w Pascalu i jest aktywnie rozwijany – https://castle-engine.io/
Lazarus to darmowe IDE podobne do Delphi dla Free Pascal. Ostatnie wydanie miało miejsce tydzień temu.
MAD Pascal to cross-compiler – kompilator 32-bitowy na PC skierowany na Atari XL/XE.
ADA

Pascal dał początek jeszcze jednemu językowi! Nazwany na cześć pierwszej programistki w historii, hrabiny Ady Lovelace, język Ada nie jest tak znany jak powinien być, ale na pewno jest solidnym, unowocześnionym potomkiem Pascala, dla różnych przypadków użycia.
Ada, stworzona pod koniec lat 70., z pierwszą implementacją opublikowaną w 1983 roku, jest określana jako “ekstremalnie silnie typowana” i “wspierająca projektowanie poprzez umowy (DbC, design by contract)”, ale powiedziałbym, że nazwanie jej “paranoiczną” jest również fair. Jeśli program w Adzie w ogóle się kompiluje, prawdopodobnie już rozpatruje wszystkie przypadki brzegowe.
Niektóre funkcje Ady są dziś niezwykle warte uwagi – wyraźna współbieżność, zadania, synchroniczne przesyłanie wiadomości, chronione obiekty i niedeterminizm.
Miała tzw. generyki (generyczne/parametryzowane typy) od momentu jej zaprojektowania w 1977 roku, i była pierwszym językiem, który je spopularyzował. C++ dodał je w 1991 roku, 14 lat później. Golang, znacznie nowszy język, dodał je w 2022 roku, 45 lat później.
Ada miała też wbudowaną składnię dla współbieżności, co wtedy było luksusem (kto miał w 1977 roku wieloprocesorowy komputer?), a dzisiaj jest jednym z podstawowych aspektów poprawy wydajności oprogramowania (“wszyscy” mają co najmniej 6 rdzeni w 2024 roku).
Język programowania Ada został początkowo zaprojektowany na podstawie kontraktu z Departamentem Obrony Stanów Zjednoczonych (DoD) od 1977 do 1983 roku dla zastąpienia ponad 450 języków programowania używanych w DoD w tamtym czasie. Przez ostatnie 30 lat stał się de facto standardem dla deweloperów aplikacji o wysokiej integralności, np. do zastosowań wojskowych. Jest szczególnie przeznaczony dla dużych, długo działających aplikacji, gdzie niezawodność, wydajność, bezpieczeństwo i ochrona są kluczowe.
https://www.adacore.com/industries/defense
Chociaż język ten jest twoim najlepszym przyjacielem gdy chcesz pisać oprogramowanie dla swojego reaktora jądrowego (przykład z Czech, dokument “Weryfikacja i walidacja oprogramowania związana z kontrolą i pomiarem elektrowni jądrowych” również wspomina “Używanie nowoczesnych języków czasu rzeczywistego takich jak ADA i OCCAM.” jako najlepszy punkt wyjścia dla określenia takiej formalizowanej weryfikacji i walidacji), lub systemów wojskowych (cytat powyżej), nigdy nie zdobył takiej popularności jak wiele innych.
Składnia i krzywa uczenia się dla Ady mogą być postrzegane jako trudniejsze niżw przypadku innych języków, co może odstraszyć niektórych deweloperów.
Język, jak zwykle, nie umarł. Ostatnia specyfikacja pochodzi z 2022 roku.
Wygląda na to, że języki, które używają więcej i dłuższych słów, tracą na popularności w czasach, gdy wszyscy się spieszą.
Wyrazy begin i end są mniej preferowane niż { i }procedure i function to sporo liter. Inne języki korzystają z func, fn, a nawet niczego (jak (args) => body we współczesnym JS).
Wyżej wymieniona obserwacja dotyczy zarówno języków ludzkich, jak i programowania.
Dodatkowe zasoby: linki i media
Niklaus Wirth, Algorytmy i struktury danych na Archive.org – do wypożyczenia
Dlaczego Forth? – post na Reddicie
Historia języka C na cppreference.com
Zaawansowane edytory tekstów, które mieliśmy 30 lat temu… i które zaginęły – niedawny i interesujący post na temat interfejsów tekstowych Turbo Pascal i podobnych!